 Хеширование — это метод, с помощью которого мы можем сопоставить большое количество данных с таблицей меньшего размера, используя “хеш-функцию”.
Хеширование — это метод, с помощью которого мы можем сопоставить большое количество данных с таблицей меньшего размера, используя “хеш-функцию”.
Используя метод хеширования, мы можем выполнять поиск данных быстрее и эффективнее по сравнению с другими методами поиска, такими как линейный и двоичный поисками.
Давайте разберемся в технике хеширования на примере из этой статьи.
Хеширование в C++
Давайте возьмем пример библиотеки университета, в которой хранятся тысячи книг. Книги расположены в соответствии с предметами, отделами и т.д. Но все же в каждом разделе будет множество книг, что сильно затрудняет поиск нужной книги.
Таким образом, чтобы преодолеть эту трудность, мы присваиваем каждой книге уникальный номер или ключ, чтобы мы мгновенно находили местоположение книги. Такой поиск достигается за счет хеширования.
Продолжая наш пример с библиотекой, вместо идентификации каждой книги на основе ее отдела, темы, раздела и т.д., что может привести к очень длинной строке, мы вычисляем уникальное целочисленное значение или ключ для каждой книги в библиотеке, используя уникальную функцию, и сохраняем эти ключи в отдельной таблице.
Уникальная функция, упомянутая выше, называется “Хэш-функцией”, а отдельная таблица называется “Хэш-таблицей”. Хэш-функция используется для сопоставления заданного значения с определенным уникальным ключом в хэш-таблице. Это приводит к более быстрому доступу к элементам. Чем эффективнее функция хеширования, тем эффективнее будет сопоставление каждого элемента уникальному ключу.
Давайте рассмотрим хеш-функцию h (x), которая отображает значение “x” в “x%10” в массиве. Для заданных данных мы можем создать хэш-таблицу, содержащую ключи или хэш-коды или хэши, как показано на схеме ниже:
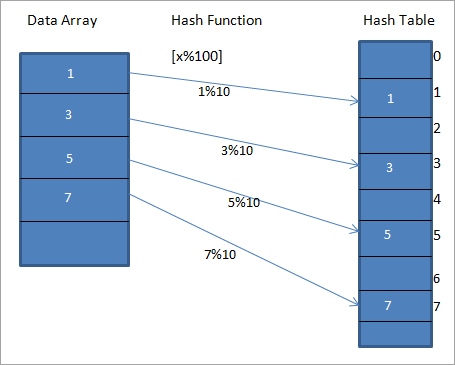
На приведенной выше схеме можно видеть, что записи в массиве сопоставляются с их позициями в хеш-таблице, с помощью хеш-функции.
Таким образом, мы можем сказать, что хеширование реализуется с использованием двух шагов, как указано ниже:
1) Значение преобразуется в уникальный целочисленный ключ или хэш, с помощью хэш-функции. Используется в качестве индекса для хранения исходного элемента, который попадает в хеш-таблицу.
На приведенной выше схеме значение 1 в хэш-таблице является уникальным ключом для хранения элемента 1 из массива данных, указанного на LHS схеме.
2) Элемент из массива данных хранится в хэш-таблице, откуда его можно быстро извлечь, с помощью хэшированного ключа. На приведенной выше схеме вы увидели, что мы сохранили все элементы в хеш-таблице после вычисления их соответствующих местоположений, с помощью хеш-функции. Мы можем использовать следующие выражения для получения значений хэша и индекса:
| hash = hash_func(key) index = hash % array_size |
Хеш-функция
Мы уже говорили, что эффективность отображения зависит от эффективности хэш-функции, которую мы используем.
Хэш-функция в основном должна соответствовать следующим требованиям:
- Простота вычисления: хеш-функция, должна легко вычислять уникальные ключи.
- Меньше конфликтов: когда элементы соответствуют одинаковым значениям ключа, возникает коллизия. В используемой хэш-функции должно быть минимальное количество коллизий, насколько это возможно.
- Равномерное распределение: хэш-функция должна приводить к равномерному распределению данных по хэш-таблице, и тем самым предотвращать кластеризацию.
Хеш-таблица в C++
Хеш-таблица или хеш-карта — это структура данных, в которой хранятся указатели на элементы исходного массива данных.
В нашем примере с библиотекой, хэш-таблица для библиотеки будет содержать указатели на каждую из книг в библиотеке.
Наличие записей в хэш-таблице упрощает поиск определенного элемента в массиве.
Как уже было показано, хеш-таблица использует хеш-функцию для вычисления индекса в массиве сегментов или слотов, с помощью которых можно найти желаемое значение.
Рассмотрим другой пример со следующим массивом данных:

Предположим, что у нас есть хэш-таблица размером 10, как показано ниже:

Теперь давайте воспользуемся хэш-функцией, приведенной ниже:
| Hash_code = Key_value % size_of_hash_table |
Это будет приравниваться к Hash_code = Key_value%10
Используя приведенную выше функцию, мы сопоставляем значения ключей с местоположениями хэш-таблицы, как показано ниже:
| Элемент данных | Хеш-функция | Хеш-код |
| 25 | 25%10 = 5 | 5 |
| 27 | 27%10 = 7 | 7 |
| 46 | 46%10 = 6 | 6 |
| 70 | 70%10 = 0 | 0 |
| 89 | 89%10 = 9 | 9 |
| 31 | 31%10 = 1 | 1 |
| 22 | 22%10 = 2 | 2 |
Используя приведенную выше таблицу, мы можем представить хэш-таблицу следующим образом:
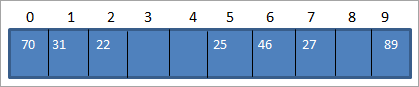
Таким образом, когда нам нужно получить доступ к элементу из хэш-таблицы, для выполнения поиска потребуется всего O (1) времени.
Конфликт
Обычно мы вычисляем хеш-код с помощью хеш-функции, чтобы мы могли сопоставить значение ключа с хеш-кодом в хеш-таблице. В приведенном выше примере массива данных, давайте вставим значение 12. В этом случае hash_code для значения ключа 12 будет 2. (12%10 = 2).
Но в хэш-таблице у нас уже есть сопоставление с ключом-значением 22 для hash_code 2, как показано ниже:
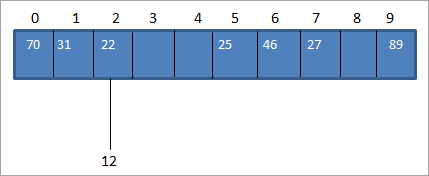
Как показано выше, у нас один и тот же хэш-код для двух значений, 12 и 22, т.е. 2. Когда одно или несколько значений ключа соответствуют одному и тому же местоположению, это приводит к коллизии (конфликтам). Таким образом, местоположение хэш-кода уже занято одним ключевым значением, и есть другое ключевое значение, которое необходимо поместить в то же место.
В случае хеширования, даже если у нас есть хэш-таблица очень большого размера, обязательно возникнет коллизия. Это потому, что мы находим небольшое уникальное значение для большого ключа в целом, следовательно, вполне возможно, что одно или несколько значений будут иметь один и тот же хэш-код в любой момент времени.
Учитывая, что при хешировании конфликт неизбежен, мы всегда должны искать способы предотвращения или разрешения их. Существуют различные методы разрешения конфликтов, которые мы можем использовать.
Методы разрешения конфликтов
Ниже приведены методы, которые мы можем использовать для разрешения коллизий в хэш-таблице.
Открытое хеширование
Это наиболее распространенный метод разрешения конфликтов. Этот метод называют открытое хеширование, и он реализуется с использованием связного списка.
В технике отдельных цепочек каждая запись в хэш-таблице представляет собой связный список. Когда ключ совпадает с хэш-кодом, он вводится в список, соответствующий этому конкретному хэш-коду. Таким образом, когда два ключа имеют одинаковый хэш-код, то обе записи вводятся в связный список.
Для приведенного выше примера ниже представлена отдельная цепочка:
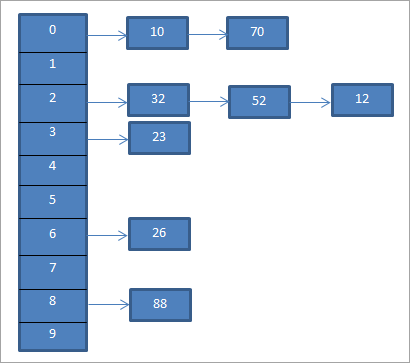
Приведенная выше схема представляет цепочку. Здесь мы используем функцию mod (%). Видно, что когда два значения ключа соответствуют одному и тому же хэш-коду, мы связываем эти элементы с этим хэш-кодом, используя связный список.
Если ключи равномерно распределены по хэш-таблице, то среднее время поиска конкретного ключа зависит от среднего количества ключей в этом связном списке. Таким образом, раздельное связывание остается эффективным даже при увеличении количества записей по сравнению с ячейками.
Наихудший случай для отдельной цепочки — это когда все ключи соответствуют одному и тому же хэш-коду и, таким образом, вставляются только в один связанный список. Следовательно, нам нужно искать все записи в хэш-таблице, которые пропорциональны количеству ключей в таблице.
Линейное зондирование (открытая адресация / закрытое хеширование)
При открытой адресации или методе линейного зондирования все записи хранятся в самой хэш-таблице. Когда значение ключа сопоставляется с хэш-кодом, а позиция, на которую указывает хэш-код, не занята, в это местоположение вставляется значение ключа.
Если позиция уже занята, то с помощью последовательности поиска значение ключа вставляется в следующую позицию, которая не занята в хэш-таблице.
Для линейного зондирования хэш-функция может изменяться, как показано ниже:
| hash = hash % hashTableSize hash = (hash + 1) % hashTableSize hash = (hash + 2) % hashTableSize hash = (hash + 3) % hashTableSize |
Видно, что в случае линейного зондирования интервал между последовательными зондами постоянен, т.е. 1:
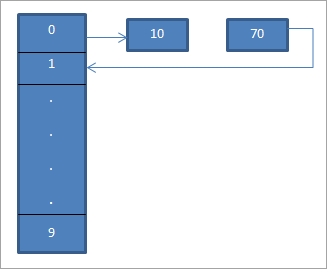
На приведенной выше схеме видно, что в 0-м местоположении мы вводим 10, используя хеш-функцию “hash = hash%hash_tableSize”.
Теперь элемент 70 также приравнивается к местоположению 0 в хеш-таблице. Но это место уже занято. Следовательно, используя линейное зондирование, мы найдем следующее местоположение, равное 1. Поскольку это место не занято, мы помещаем ключ 70 в это место, как показано стрелкой.
Результирующая хэш-таблица показана ниже:

Линейное зондирование может страдать от проблемы “первичной кластеризации”, при которой существует вероятность того, что непрерывные ячейки могут быть заняты, и вероятность вставки нового элемента уменьшается.
Кроме того, если два элемента получают одинаковое значение при первой хэш-функции, то оба этих элемента будут следовать одной и той же последовательности зондирования.
Квадратичное зондирование
Квадратичное зондирование — это то же самое, что и линейное зондирование, с единственной разницей, заключающейся в интервале, используемом для зондирования. Как следует из названия, этот метод использует нелинейное или квадратичное расстояние для заполнения слотов при возникновении конфликтов вместо линейного расстояния.
При квадратичном зондировании интервал между слотами вычисляется путем добавления произвольного полиномиального значения к уже хэшированному индексу. Этот метод значительно уменьшает первичную кластеризацию, но не улучшает вторичную кластеризацию.
Двойное хеширование
Техника двойного хеширования аналогична методу линейного зондирования. Единственное различие между двойным хешированием и линейным зондированием заключается в том, что в технике двойного хеширования интервал, используемый для зондирования, вычисляется с использованием двух хэш-функций. Поскольку мы применяем хэш-функцию к ключу один за другим, это устраняет первичную кластеризацию, а также вторичную кластеризацию.
Разница между открытым хешированием и открытой адресацией
| Открытое хеширование | Открытая адресация |
| Значения ключей могут храниться вне таблицы с помощью отдельного связного списка. | Значения ключей должны храниться только внутри таблицы. |
| Количество элементов в хеш-таблице может превышать размер хеш-таблицы. | Количество элементов, присутствующих в хеш-таблице, не будет превышать количество индексов в хеш-таблице. |
| Удаление эффективно в данной технике хеширования. | Удаление затруднительно и менее эффективно. |
| Поскольку для каждого местоположения поддерживается отдельный связный список, занимаемое пространство велико. | Поскольку все записи размещаются в одной таблице, занимаемое место меньше. |
Реализация хеш-таблицы на C++
Мы можем реализовать хеширование, используя массивы или связные списки для программирования хеш-таблиц. В C++ есть функция под названием “хэш-карта” (hash map), которая представляет собой структуру, подобную хэш-таблице, но каждая запись представляет собой пару ключ-значение. В C++ это называется хэш-карта или просто карта. Хэш-карта в C++ обычно неупорядочена.
В стандартной библиотеке шаблонов (STL) C++ определен заголовок <map>, который реализует функциональность карт. Про карты STL вы можете прочитать в этой статье.
Следующая реализация предназначена для хеширования с использованием связных списков в качестве структуры данных для хэш-таблицы. Мы также используем открытое хеширование в качестве метода разрешения конфликтов в этой реализации:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
#include&amp;lt;iostream&amp;gt; #include &amp;lt;list&amp;gt; using namespace std; class Hashing { int hash_bucket; // Количество сегментов // Указатель на массив, содержащий сегменты list&amp;lt;int&amp;gt; *hashtable; public: Hashing(int V); // конструктор // вставляет ключ в хэш-таблицу void insert_key(int val); // удаляет ключ из хэш-таблицы void delete_key(int key); // хэш-функция для сопоставления значений с ключом int hashFunction(int x) { return (x % hash_bucket); } void displayHash(); }; Hashing::Hashing(int b) { this-&amp;gt;hash_bucket = b; hashtable = new list&amp;lt;int&amp;gt;[hash_bucket]; } //вставка в хэш-таблицу void Hashing::insert_key(int key) { int index = hashFunction(key); hashtable[index].push_back(key); } void Hashing::delete_key(int key) { // получить хэш-индекс для ключа int index = hashFunction(key); // найдите ключ в (inex)-ом списке list &amp;lt;int&amp;gt; :: iterator i; for (i = hashtable[index].begin(); i != hashtable[index].end(); i++) { if (*i == key) break; } // если ключ найден в хэш-таблице, удалить его if (i != hashtable[index].end()) hashtable[index].erase(i); } // отображение хэш-таблицы void Hashing::displayHash() { for (int i = 0; i &amp;lt; hash_bucket; i++) { cout &amp;lt;&amp;lt; i; for (auto x : hashtable[i]) cout &amp;lt;&amp;lt; " --&amp;gt; " &amp;lt;&amp;lt; x; cout &amp;lt;&amp;lt; endl; } } // основная программа int main() { // массив, содержащий ключи для сопоставления int hash_array[] = {11,12,21, 14, 15}; int n = sizeof(hash_array)/sizeof(hash_array[0]); Hashing h(7); // Количество сегментов = 7 //вставить ключи в хэш-таблицу for (int i = 0; i &amp;lt; n; i++) h.insert_key(hash_array[i]); // отображение хэш-таблицы cout&amp;lt;&amp;lt;"Hash table created:"&amp;lt;&amp;lt;endl; h.displayHash(); // удалить 12 из хэш-таблицы h.delete_key(12); // отображение хэш-таблицы cout&amp;lt;&amp;lt;"Hash table after deletion of key 12:"&amp;lt;&amp;lt;endl; h.displayHash(); return 0; } |
Вывод данных:
| Hash table created: 0 –> 21 –> 14 1 –> 15 2 3 4 –> 11 5 –> 12 6Hash table after deletion of key 12: 0 –> 21 –> 14 1 –> 15 2 3 4 –> 11 5 6 |
На выходе отображается хэш-таблица, которая создается размером 7. Мы используем цепочку для разрешения коллизий, и выводим хэш-таблицу после удаления одного из ключей.
Применение хеширования
1) Проверка паролей: проверка паролей обычно выполняется с помощью криптографических хэш-функций. Когда пароль введен, система вычисляет хэш пароля, и затем отправляется на сервер для проверки. На сервере хранятся хэш-значения исходных паролей.
2) Структуры данных: различные структуры данных, такие как unordered_set и unordered_map в C++, словари в python или C#, HashSet и hash map в Java, используют пару ключ-значение, в которой ключи являются уникальными значениями. Значения могут быть одинаковыми для разных ключей. Для реализации этих структур данных используется хеширование.
3) Дайджест сообщений: это еще одно применение, использующее криптографический хэш. В дайджестах сообщений мы вычисляем хэш для отправляемых и принимаемых данных или даже файлов, и сравниваем их с сохраненными значениями, чтобы убедиться, что файлы данных не подделаны. Наиболее распространенным алгоритмом здесь является “SHA 256” (семейство криптографических алгоритмов).
4) Работа компилятора: когда компилятор компилирует программу, ключевые слова для языка программирования хранятся иначе, чем другие идентификаторы. Компилятор использует хэш-таблицу для хранения этих ключевых слов.
5) Индексация базы данных: хэш-таблицы используются для индексации базы данных и структур данных на основе дисков.
6) Ассоциативные массивы: ассоциативные массивы — это массивы, индексы которых имеют тип данных, отличный от целочисленных строк или других типов объектов. Хеш-таблицы можно использовать для реализации ассоциативных массивов.
Итог
Хеширование является наиболее широко используемой структурой данных, поскольку для операций вставки, удаления и поиска требуется постоянное время O (1). Хеширование в основном реализуется с помощью хэш-функции, которая вычисляет уникальное значение меньшего ключа для больших записей данных. Мы можем реализовать хеширование с использованием массивов и связных списков.
Всякий раз, когда одна или несколько записей данных соответствуют одним и тем же значениям ключей, это приводит к коллизии. Мы показали вам различные методы разрешения конфликтов, включая линейное зондирование, открытое хеширование и т.д., а также показали вам реализацию хеширования на C ++.
В заключение мы можем сказать, что хеширование на сегодняшний день является самой эффективной структурой данных в мире программирования.
В следующей статье мы расскажем о типах деревьев, методах обхода и базовой терминологии со схемами и примерами программ.
С Уважением, МониторБанк