 Структура данных может быть определена как организованный набор данных, который помогает программе эффективно и быстро получать доступ к данным для того, чтобы вся программа могла работать эффективно.
Структура данных может быть определена как организованный набор данных, который помогает программе эффективно и быстро получать доступ к данным для того, чтобы вся программа могла работать эффективно.
Вы наверняка знаете, что в мире программирования данные являются центром, и все вращается вокруг данных. Если будут эффективно выполняться все операции с данными, включая хранение, поиск, сортировку, организацию и доступ к данным, то тогда наши программы будут работать правильно и стабильно.
Наша задача, найти наиболее эффективный способ хранения данных, который поможет нам создавать динамические решения. Структура данных как раз и поможет нам в поиске таких решений.
Во-первых, при организации или размещении данных в структуры нам необходимо убедиться, что расположение представляет собой объект, близкий к реальному. Во-вторых, такое устройство должно быть достаточно простым, чтобы каждый мог легко получить к нему доступ и обрабатывать его в любое время.
В этой серии статей мы подробно расскажем вам как об базовой, так и о расширенной структуре данных. Мы также подробно поговорим о различных методах поиска и сортировки, которые можно выполнять в структурах данных. Изучив эту серию статей, вы познакомитесь с каждой структурой данных и ее программированием.
Давайте рассмотрим некоторые термины, которые мы будем использовать при работе со структурами данных:
Для примера возьмем конкретного ученика. Учащийся может иметь следующие детали, представленные на схеме:
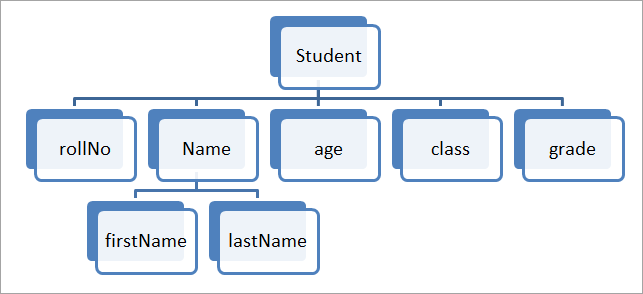
- Данные: это элементарное значение. На приведенной выше схеме номер ученического списка может быть данными.
- Групповой элемент: это элемент данных, который имеет более одного подэлемента. На приведенной выше схеме Student_name имеет имя и фамилию.
- Запись: это набор элементов данных. В приведенном выше примере элементы данных, такие как номер списка учащихся, имя, класс, возраст, класс и т. д., вместе образуют запись.
- Сущность: это класс записей. На приведенной выше схеме ученик является сущностью.
- Атрибут или поле: свойства объекта называются атрибутами, и каждое поле представляет собой атрибут.
- Файл: файл представляет собой набор записей. В приведенной выше схеме ученический объект может иметь тысячи записей. Таким образом файл будет содержать все эти записи.
Вы должны знать обо всех этих терминах, поскольку мы используем их время от времени при использовании различных структур данных.
Структуры данных являются основным строительным блоком программы, и как программисты, мы должны быть осторожны при выборе структуры данных. Точная структура данных, которую нужно использовать, является самым сложным решением, когда речь идет о программировании.
Давайте обсудим необходимость структуры данных в программировании.
Необходимость структуры данных в программировании
Поскольку объем данных продолжает расти, программы (приложения) становятся все более и более сложными, поэтому программисту становится все труднее управлять этими данными, а также программным обеспечением.
Как правило, в любой момент программа может столкнуться со следующими препятствиями:
1) Поиск больших объемов данных: при обработке и хранении большого объема данных в любой момент времени нашей программе может потребоваться поиск определенных данных. Если данные слишком велики и не организованы должным образом, получение необходимых данных займет много времени.
Когда мы используем структуры данных для хранения и организации данных, поиск данных становится быстрее и проще.
2) Скорость обработки: Неорганизованные данные могут привести к снижению скорости обработки, поскольку много времени будет потрачено впустую на получение и доступ к данным.
Если мы правильно организуем данные в структуру данных при хранении, то мы не будем тратить время на такие действия, как извлечение. Вместо этого мы можем сосредоточиться на обработке данных для получения желаемого результата.
3) Несколько одновременных запросов. Многие программы, в наши дни. должны выполнять одновременный запрос к данным. Эти запросы должны эффективно обрабатываться для бесперебойной работы приложений.
Если наши данные будут храниться просто случайным образом, то мы не сможем обрабатывать все параллельные запросы одновременно. Таким образом, это мудрое решение организовать данные в надлежащей структуре данных, чтобы свести к минимуму время обработки параллельных запросов.
Классификация структуры данных
Структуры данных, используемые в C++, можно классифицировать следующим образом:
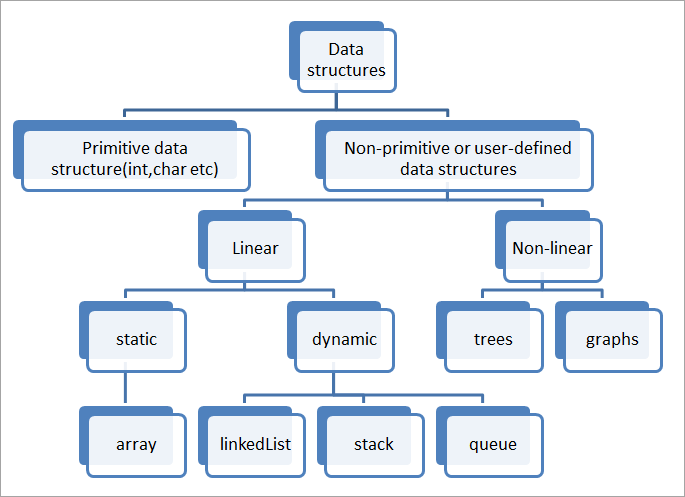
Структура данных — это способ организации данных. Таким образом, мы можем классифицировать структуры данных, как показано, на примитивные (Primitive data structure) или стандартные структуры данных и непримитивные (Non-primitive) или определяемые пользователем структуры данных.
Мы вам показали все типы данных, поддерживаемые в C++. Поскольку это также способ организации данных, то это стандартная структура данных.
Другие структуры данных не являются примитивными, и пользователь должен определить их перед использованием в программе. Эти определяемые пользователем структуры данных далее подразделяются на линейные и нелинейные структуры данных.
Линейная структура данных
В линейных структурах данных все элементы расположены линейно или последовательно. Каждый элемент в линейной структуре данных имеет предшественника (предыдущий элемент) и преемника (следующий элемент).
Линейные структуры данных далее делятся на статические и динамические структуры данных. Статические структуры данных обычно имеют фиксированный размер, и после того, как их размер объявлен во время компиляции, его нельзя будет изменить. Динамические структуры данных могут динамически изменять свой размер и подстраивать их под себя.
Наиболее популярным примером линейной статической структуры данных является массив.
Массив (Array)
Массив представляет собой последовательный набор элементов одного типа. Доступ к каждому элементу массива можно получить, используя его позицию в массиве, называемую индексом или нижним индексом массива. Имя массива указывает на первый элемент массива:
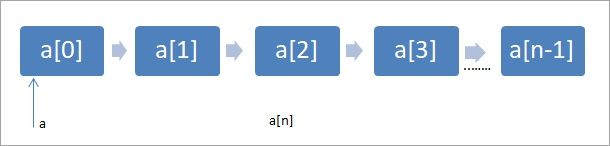
Выше показан массив «a» из n элементов. Элементы пронумерованы от 0 до n-1. Размер массива (в данном случае n) также называется размерностью массива. Как показано на рисунке выше, имя массива указывает на первый элемент массива.
Массив является простейшей структурой данных и эффективен, поскольку к элементам можно обращаться напрямую с помощью индексов. Если мы хотим получить доступ к третьему элементу массива, нам просто нужно выбрать a[2].
Но добавлять или удалять элементы массива сложно. Поэтому мы используем массивы только в простых программах и приложениях, где не требуется добавление/удаление элементов.
Популярными линейными динамическими структурами данных являются связный список, стек и очередь.
Связный список
Связный список — это набор узлов. Каждый узел содержит элемент данных и указатель на следующий узел. Узлы можно добавлять и удалять динамически. Связный список может быть односвязным списком, в котором каждый узел имеет указатель только на следующий элемент. Для последнего элемента указатель next устанавливается равным нулю.
В двусвязном списке каждый узел имеет два указателя: один на предыдущий узел, а второй — на следующий узел. Для первого узла предыдущий указатель равен нулю, и для последнего узла следующий указатель равен нулю.

Как показано на схеме выше, начало списка называется головой, а конец связного списка — хвостом. Как показано выше, каждый узел имеет указатель на следующий элемент. Мы можем легко добавлять или удалять элементы, изменяя указатель на следующий узел.
Стек (Stack)
Стек — это линейная структура данных, в которой элементы могут быть добавлены или удалены только с одного конца, известного как «Top» (вершина) стека. Таким образом, стек демонстрирует тип доступа к памяти LIFO (Last In, First Out).

Как показано выше, элементы в стеке всегда добавляются с одного конца и также удаляются с одного конца. Это называется вершиной стека. Когда элемент добавляется, он перемещается вниз по стеку, а вершина стека увеличивается на одну позицию.
Точно так же, когда элемент удаляется, вершина стека уменьшается. Когда стек пуст, вершине стека присваивается значение -1. Есть две основные операции «Push» и «Pop», которые выполняются в стеке.
Очередь (Queue)
Очередь — это еще одна линейная структура данных, в которой элементы добавляются с одного конца, называемого «rear» (задним), и удаляются с другого конца, называемого «front» (передним). Очередь демонстрирует FIFO (First In, First Out) тип методологии доступа к памяти:
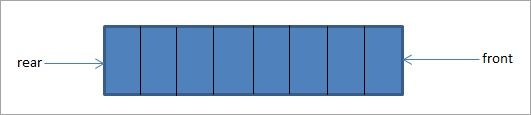
На приведенной выше схеме показана очередь с задним и передним концами. Когда очередь пуста, задний и передний указатели совпадают.
Нелинейная структура данных
В нелинейных структурах, данные располагаются не последовательно, а нелинейно. Элементы соединены друг с другом нелинейным расположением.
Нелинейные структуры данных — это деревья и графы.
Деревья
Деревья представляют собой нелинейные многоуровневые структуры данных, имеющие иерархическую связь между элементами. Элементы дерева называются узлами.
Верхний узел называется корнем дерева. Корень может иметь один или несколько дочерних узлов. Последующие узлы также могут иметь один или несколько дочерних узлов. Узлы, не имеющие дочерних узлов, называются листовыми узлами.
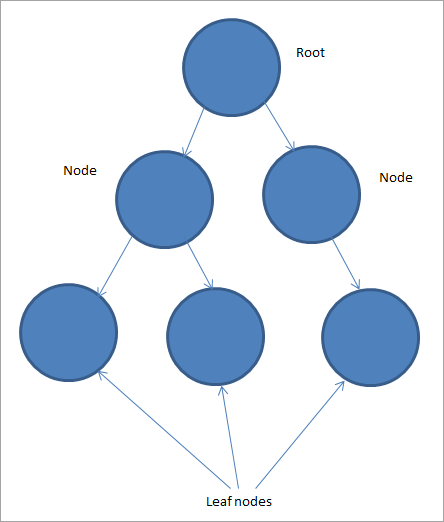
На приведенной выше диаграмме мы показали дерево с 6 узлами. Из них, три узла являются листовыми узлами, один самый верхний узел является корневым, а остальные являются дочерними узлами. В зависимости от количества узлов, дочерних узлов и т. д. или отношений между узлами получаются разные типы деревьев.
Графы
Графы представляют собой набор узлов, называемых вершинами, соединенных друг с другом с помощью связей, называемых ребрами. Внутри граф может быть цикл, т.е. одна и та же вершина может быть как начальной, так и конечной точкой определенного пути. У деревьев же никогда не может быть цикла.
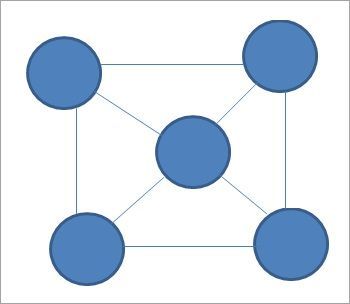
Приведенная выше схема представляет собой неориентированные графы. Также могут быть ориентированные графы.
Операции со структурой данных
Все структуры данных выполняют различные операции над своими элементами.
Они являются общими для всех структур данных и перечислены ниже:
- Поиск: эта операция выполняется для поиска определенного элемента или ключа. Наиболее распространенными алгоритмами поиска являются последовательный/линейный поиск и бинарный поиск.
- Сортировка. Операция сортировки включает в себя упорядочение элементов в структуре данных в определенном порядке по возрастанию или по убыванию. Для структур данных доступны различные алгоритмы сортировки. Наиболее популярными среди них являются: быстрая сортировка, сортировка выбором, сортировка слиянием и др.
- Вставка: операция вставки связана с добавлением элемента в структуру данных. Это самая важная операция, и в результате добавления элемента расположение меняется, и нужно позаботиться о том, чтобы структура данных осталась нетронутой.
- Удаление: операция удаления удаляет элемент из структуры данных. Те же условия, которые должны учитываться при вставке, должны выполняться и в случае операции удаления.
- Обход: мы обходим структуру данных, когда посещаем каждый элемент в структуре. Обход необходим для выполнения определенных специфических операций со структурой данных.
В наших следующих статьях мы с вами изучим различные методы поиска и сортировки, которые будут выполняться в структурах данных.
Преимущества структуры данных
- Абстракция: структуры данных часто реализуются как абстрактные типы данных. Пользователи получают доступ только к его внешнему интерфейсу, не беспокоясь о базовой реализации. Таким образом, структура данных обеспечивает уровень абстракции.
- Эффективность: Правильная организация данных приводит к эффективному доступу к данным, что делает программы более эффективными. Также, мы можем выбрать правильную структуру данных в зависимости от наших требований.
- Повторное использование: мы можем повторно использовать структуры данных, которые мы разработали. Их также можно скомпилировать в библиотеку и передать клиенту.
Итог
На этом мы завершаем данную статью по введению в структуры данных. В этой статье мы как можно кратко представили каждую из структур данных.
В нашей следующей статье мы поговорим об алгоритмах поиска в C++.
С Уважением, МониторБанк